2024. 5. 31. 00:25ㆍReview/- Network
SHViT: Single-Head Vision Transformer with Memory Efficient Macro Design
Motiviation
Recently, efficient Vision Transformers use 4x4 patch embeddings and a 4-stage structure at the macro level, while utilizing sophisticated attention with multi-head configuration at the micro level. Authors aims to address computational redundancy at all design levels in a memory-efficient manner. they discover that using larger-stride patchify stem not only reduces memory access costs but also achieves competitive performance with reduced spatial redundancy from the early stages. Furthermore they suggest that attention layers in the early stages can be substituted with convolutions, and several attention heads in the latter stages are computationally redundant. To handle this, they introduce a single-head attention module that prevents head redundancy and boosts accuracy by parallelly combining global and local information.
Main Idea
Compared to CNNs, ViTs excel in modeling long-range dependencies and scale effectively with large amounts of training data and model parameters. Desptie these advantages, the lack of inductive bias lead to ViTs more training data, and global attentionmodule incurs quadratic computational complexity with respect to the image size. Recently for real-time constraints studies have also proposed eficient models following similar strategies. 1) efficient architect - macro design, 2) efficient Multi-Head Self-Attention(MHSA) - micro design. In this paper authors explore the reducndancy at all design levels, and propose memory-efficient solutions.

Macro design
To identify computational redundancy in macro design, they concentrate on patch embedding size. early stages from traditional macro design with fewer channels exhibit a severe speed bottleneck due to the large number of tokens. But using a 3-stage design with 16x16 patchify stem does not lead to a significant drop in performance without bottleneck. These result demonstrate that there is considerable spatial redundancy in the early stages, efficient macro design is more crucial for the model to achieve competitive performance within strict latency limits.

Micro design
Most eficient MHSA methods have primarily focused on effective spatial token mixing. Due to the efficient micro design we use token representation with increased semantic density. Thus authors turn their focus to the channel(head) redundancy present in attention layers. Tehy find that there is a noticeable redundancy in multi-head mechanism, particularly in the latter stages. They then propose a novel Single-Head Self-Attention (SHSA) to reduce the computational redundancy. In SHSA, self-attention with a single head is applied to just a subset of the input channels, while the others re main unchanged. SHSA layer not only eliminates the computational redundancy from MHSA but also reduce memory accesss cost. These efficienies enable stacking more blocks with a larger width, leading to performance improvement within the same computational budget.

They also deleve into the multi-head redundancy of prevailing tiny ViT models through three experiments: attentionmap visualization, head similarity analysis, and head ablation study. For head similarity analysis, they measure the average cosine similarity between each head and other heads inthe same layer. For head ablation study, they evaluate the performance impact by nullifying the output of som heads
First of all in the early stages, they observe that the top-performing heads tend to operate in a convolution-like manner, while heads that have minimal impact on performance when removed typically process information more globally. the model using attention layers in the first stage exhigits a less favorable speed-accuracy trade-off. Hence, for efficency they use convolutions with spatial inductive bias as the token mixer in the initial stage.
In the latter stages, they find that there is a lot of redundancy both at the feature and prediction levels. In the experiment of removing one head, they observe that the majority of heads can be removed without deviating too much from the original accuracy.
Single-Head Self-Attention
SHSA simply applies an attention layer with a single head on only a poart of the input channels($C_p$=$rC$). they set $r$ to 1/4.67 as a default. SHSA layer can be described as:

$W^Q$, $W^K$, $W^V$, $W^O$ are projection weights, $d_{qk}$ is the dimension of the query and key (set to 16 as a default). SHSA can be interpreted as sequentially sequentially stretching the previously parallel-computed redundant heads along the block-axis.
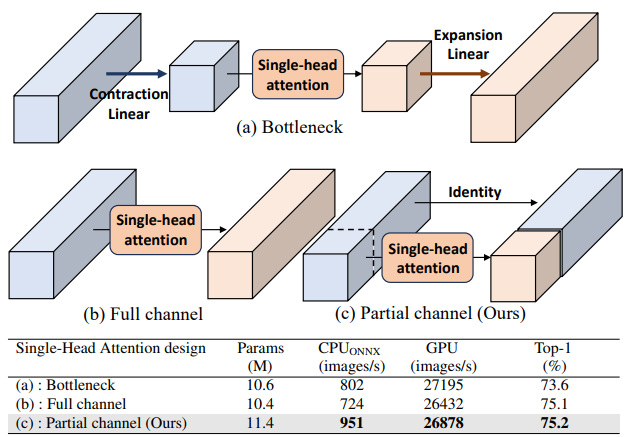
They also explore various single-head designs. (a) is combines conbolution and attention layers. Proposed partial channel approach with preceding convolution memory-efficiently. For effective utilization of the attention layer, Layer Normalization is essential. meanwhile, to implement a multi-head approach, data movements like reshape operation are required. Consequently a large portion of MHSA's runtime is taken up by memory-bound operations like reshaping and normalization. By minimizing the use of memory-bound operations or applying them to fewer input channel, the SHSA module can fully leverage the computing power of GPUs/CPUs.

Single-Head Vision Transformer

Given an input image, they first apply four 3x3 strided convolution layers to it. Their overlapping patchify stem can extract better local representations. Then the tokens pass through three stages of stacked SHViT blocks. A SHViT block consists of three modules: Depthwise Convolution (DWConv) layer for local feature aggregation or conditional position embedding, Single-Head Self-Attention (SHSA) layer for modeling global contexts, Feed-Forward-Network (FFN) for channel interaction. They do not use the SHSA layer in the first stage. To reduce tokens without information loss, they utilize an efficient downsampling layer, which is composed of two stage 1 blocks, with an inverted residual block (stride-2) placed between them. Finally, the global average polling and fully connected layer are used to output the predictions.
Experiments
All models are traqined from scratch. They also validate their model as an efficient vision backbone for object detection and instance segmentation on COCO with RetinaNet and Mask R-CNN on mmdetection library.
SHViT on ImageNet-1K Classification
The results demonstrate that their proposed memory-efficient macro design has a more significant impact on the speed-accuracy tradeoff than efficient attention variants or highly simple operations like pooling.

Comparison with efficient CNNs. SHViT-S1 achieves 5.4% higher accuracy than MobileNetV3-Small. Compared to ShuffleNetV2 x2.0, SHViT-S2 obtains slightly better performance with 2.2x and 2.5x speed improvements. Compared to the recent FsterNet-T1, SHViT-S3 not only achieves 1.2$ higher accuracy but also runs faster: 15.1%.
Comparison with efficient ViTs and hybrid models. SHViT-S1 has 10% and 42% higher throughput than EfficientViT-M2, showing better performance 2%. SHViT-S3 obtains similar accuracy to PoolFormer-S12, but it uses 3x fewer FLOPs, is 3.8x faster.
Finetuning with highter resolution. They also finetune their SHViT-S4 to higher resolutions. Compared to the EfficientViT-M5${}_{r512}$, SHViT-S4${}_{r384}$ attains competive performance, even when trained at a lower resolution. SHViT-S4${}_{r384}$ is 77.4% faster, and achieves 82.0% top-1 accuracy with throughput of 3957 images/s.
Distillation results. Notably, their models outperform competing models in both speed and accuracy.
Mobile Layency Evaluation. We also verify the effectiveness of theirmodel on the mobile device (iPhone 12). At low resolutions, SHViT-S4 is slightly slower, but at 1024 x 1024, their model achieves 34.4% and 69.7% lower latency than FastViT and EfficientFormer.


SHViT on downstream tasks
They evaluate the transfoer ability of their SHViT using two frameworks: 1) RetinaNet for object detection, 2) Mask R-CNN for instance segmentation.
Object detection. SHViT-S4 is 2.3x faster on mobile device than MobileNetV3 and outperforms it by +8.9 AP. Compared to MobileFormer, their model achieves better performance while being 3.2x and 8.2x faster.

Instance Segmentation. SHViT-S4 surpass EfficientViT and EfficientNet in speed, while delivering a substantial performance boost. As shown in the results the large-stride patchify stem with 3-stage reduces not only computational costs but also generates meaningful token representations, especially at higher resolutions.

Ablation Study
They first verify the effectiveness of their proposed SHSA layer and then conduct value of the partial ratio for SHSA layer.

Effectiveness of SHSA. They conduct an ablation study by either replacing the SHSA layer with the MHSA layer or removing it. SHSA layer exhigits a better speed-accuracy tradeoff compared to MHSA layer.
Searching for the appropriate partial ratio of SHSA. By default, they set the partial ratio to 1/ 4.67 for all SHViT models, which obtains the optimal speed-accuracy tradeoff(3, 5 vs 4). Compared to a very small value, increasing the channels moderately achieve effective performance enhancement at low costs. Also a too large value does not provide a performance boost that compensates for the accompanying costs.
Conclusion
They have investigated redundancies at both the spatial and channel dimensions of the architectural design. They then proposed 16 x 16 patch embeddings with 3-scale hierarchical representations and Single-Head Self-Attention (SHSA) to address the computational redundancies. They further present SHViT, built upon proposed macro/micro designs.
Reference
[Figure-1~6, Table-1~5]: https://arxiv.org/pdf/2401.16456
'Review > - Network' 카테고리의 다른 글
| Paper review: InternImage (CVPR 2023) (0) | 2024.08.11 |
|---|---|
| Paper review: DCNv1 (ICCV 2017) (0) | 2024.07.25 |
| Paper review: Swin Transformer (ICCV 2021) (0) | 2024.04.19 |
| Paper review: MLP-mixer (NeurIPS 2021) (0) | 2024.04.17 |
| Paper review: ViT (NeurIPS 2021) (0) | 2024.04.15 |