2024. 9. 3. 02:12ㆍReview/- Network
Deformable ConvNets v2: More Deformable, Better Results
Motivation
Through an examination of adaptive behavior from deformable convolution, authors observe that while the spatial support for its neural features conforms more closely than regular ConvNets to object structure, this support may nerver theless extend well beyond the region of interest, causing features to be influenced by irrelevant image content. To address this problem, they present a reformulation of Deformable CovNets, through increased modeling power and stronger training. They propose modulation mechanism and mimicking scheme.
Main Idea
Towards understanding Deformable ConvNets, the authors visualized the induced changes in receptive field. It is found that samples for an activation unit tend to cluster around the object on which it lies. However, the coverage over an object is inexact, exhibiting a spread of samples beyond the area of interest. In this paper authors present Deformable ConvNets v2 (DCNv2). This increase in modeling capability comes in two complementary forms. The first is the expaned use of deformable convolution layers within the network. The second is a modulation mechanism in the deformable convolution modules. To fully exploit the increased modeling capacity of DCNv2, they use knowledge distillation.
Analysis of Deformable ConvNet Behavior
Spatial Support visualization
They visualize the spatial support of network nodes by their effective receptive fields, effective sampling locations, error-bounded saliency regions.
Effective receptive fileds. Not all pixels within the receptive field of a netowrk node contribute equally to its reponse. They utilize the effective receptive field to examine the relative influence of individual pixels, but this measure does not reflect the structured influence of full image regions.
Effective sampling / bin locations. The sampling locations of convolutional layers and sampling bins in RoIpooling layers are visualized. Howerver, the relative contributions of these sampling locations are not revealed. Instead tehy visualize effective sampling locations that incorporate this information.
Error-bounded saliency regions. The response of a network node will not change if we remove image regions that do not influence it. Based on this property, they cna determine support region as the smallest image region giving the same response as the full image, within a small error bound.
Analysis with three visualization.

1. Regular ConvNets can model geometric variations to some extent, as evidenced by the changes in spatial support with respect to image content.
2. By introducing deformable convolution, the network's ability to model geometric transformation is considerably enhanced. The spatical support adapts much more to image content, with nodes on the foregound having support that covers the whole object, while nodes on the background have expanded support that encompasses greater context.
While it is evident that Deformable ConvNets have markedly improved ability to adapt to geometric vatiation in comparision to regular ConvNets, it can also be seen that eheir spatial support may extend beyond the region of interest.
More deformable ConvNets
They present changes to boost its modeling power and to help it take advantage of this increased capability.
Stacking More Deformable Conv Layers
They boldly replace more regular conv layers by their deformable counterparts. Deformable convolutions are applied in all the 3 x 3 conv layers in stages conv3~5 in ResNet-50
Modulated Deformable Modules
To futher strengthen the capability of Deformable ConvNets in manipulating spatial support regions, a modulation mechanism is introduced. The deformable ConvNets modules can not only adjust offsets in perceiving input features, but also modulate the input feature amplitudes from different spatial locations / bins. Thus the modulation mechanism provides the network module another dimension of freedom to adjust its spatial support regions.
Given a convolutional kernel of $K$ sampling locations, let $w_k$ and $p_k$ denote the weight and pre-specified offset for the $k$-th location, the modulated deformable convolution can then be expressed as

where $\Delta p_k$ and $\Delta m_k$ are the learnable offset and modulation scalar for the $k$-th location, respectively. The modulation scalar $\Delta m_k$ lies in the range [0, 1], while $\Delta p_k$ is a real number with unconstrained range. As $p + p_k + \Delta p_k$ is fractional, bilinear interpolation is applied in computing $x(p + p_k + \Delta p_k)$. Both $\Delta p_k$ and $\Delta m_k$ are obtained via a separate convolution layer applied over the sam input feature maps $x$. This convolutional layer is of the same spatial resolution and dilation as the current convolutional layer. The output is of 3K channels, where the first 2K channels correspond to the learned offsets $\{\Delta p_k\}^{K}_{k=1}$, and the remaining K channels are further fed to a sigmoid layer to obtain the modulation scalars $\{\Delta m_k\}^{K}_{k=1}$. Initial values of $\Delta p_k$ and $\Delta m_k$ are 0 and 0.5 (zero weights). The learning rates of the added conv layers for offset and modulation learning are set to 0.1 times those fo the existing layers.
The design of modulated deformable RoIpooling is similar. Given an input RoI, RoIpooling divides it into K saptial bin. Within each bin, sampling grids of even spatial intervals are applied. The sampled values on the grids are averaged to compute the bin output. Let $\Delta p_k$ and $\Delta m_k$ be the learnable offset and modulation scalar for the $k$-th bin. The output binning feature $y(k)$ is computed as

where $p_{kj}$ is the sampling location for the $j$-th grid cell in the $k$-th bin, and $n_k$ denotes the number of sampled grid cells. Binlinear interpolation is applied to obtain features $x(p_{kj}+\Delta p_k)$. The values of $\Delta p_K$ and $\Delta m_k$ are produced by a sibling branch on the input feature maps. In this branch, RoIpooling generated features on the RoI, followed by two $fc$ layers of 1024-D. On top of that, an additional fc layer produces output of 3K channels. the first 2K channels are the normalied learnable offsets, where element-wise multiplications with the RoI's width and height are compute to obtain $\{\Delta p_k\}^K_{k=1}$. The remaining K channels are normalized by a sigmoid layer to produce $\{\Delta m_k\}^K_{k=1}$. The learning rates of the added fc layers for offset learning are same as those of the existing layers.

R-CNN Feature Mimicking
The error-bounded saliency region of ta per-RoI classification node can stretch byond the RoI for both regular ConvNets and Deformable ConvNets and Deformable ConvNets. It can lead degrade the final results. So athors propose to combine the classification scores of Faster R-CNN and R-CNN to obain the final detection score. Since R-CNN classification scores are focused on cropped image content from the input RoI, incorporating them would help to alleviate the redundant context problem and improve detection accuracy. And they incorporate a feature mimic loss on the per-RoI features of deformable Faster R-CNN to force them to be similar to R-CNN features extracted form cropped images. This is intended to drive deformable Faster R-CNN to learn more "focused" feature representations like R-CNN.
Given an RoI b for feature mimicking from Faster R-CNN, the image patch corresponding to it is cropped and resized to 224 x 224 pixels. In the R-CNN branch, the backbone network operates on the resized image patch and produces feature maps of 14 x 14 spatial resolution. The feature mimic loss is enforced between $f_{RCNN}(b)$ and the $f_{FRCNN}(b), computed as

where $\Omega$ denotes the set of RoIs sampled for feature mimic training. Given an input image, 32 positive region proposals generated by RPN are randomly sampled into $\Omega$. A cross-entropy classification loss is enforced on the R-CNN classification head.

Experiments
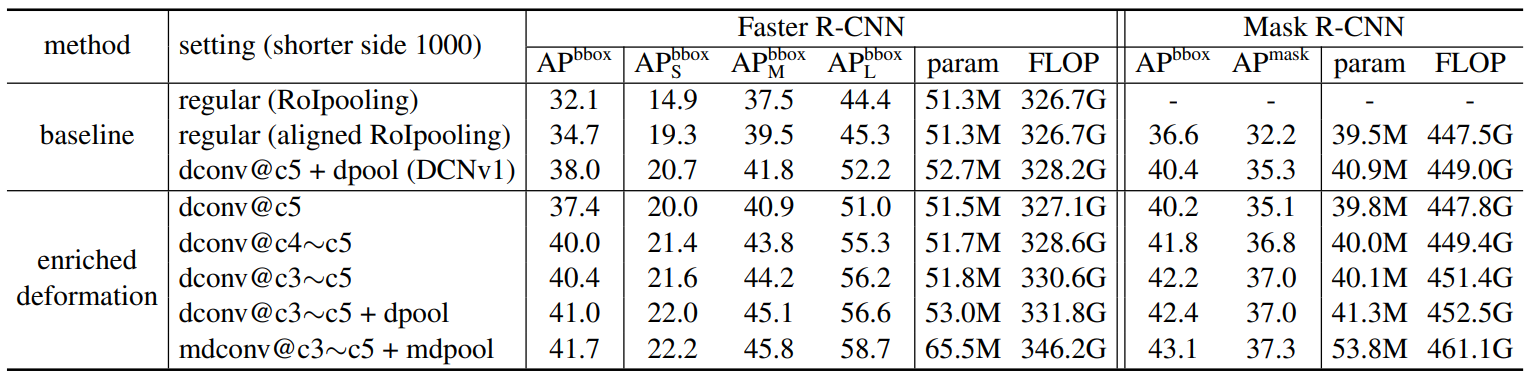
Enriched Deformation Modeling
They follow the original Deformable ConvNets paper by replacing the rlast three layers of 3 x 3 convolution in the conv5 stage and the aligned RoIpooling layer by their deformable counterparts.

R-CNN Feature Mimicking
Mimicking features of positive boxes on the object foregorund is found to be particularly effective, and the results when mimicking all the boxes or just negative boxes are much lower. The visualized spatial support regions are shown [Figure-2], which are not focused on the object foreground even with the auxiliary mimic loss. This is likely because it is beyond the representation capability of regular ConvNets to focus features on the object foreground.

Application on Stronger Backbones
For the entries of DCNv1, the regular 3 x 3 conv layers in the conv5 stage are replaced. For the entries of DCNv2 all the 3x3 conv layers in conv3~5 are replaced.

Conclusion
Spatial support of DCNv1 extends well beyond the region of interest, causing features to be influenced by irrelevant image content. In this paper authors present a reformulation of Deformable ConvNets which improves its ability to focus on pertinent image regions.
Reference
[Figure-1~3, Eq-1~2, Table-1~4]: https://arxiv.org/pdf/1811.11168
'Review > - Network' 카테고리의 다른 글
| Paper review: Rewrite the Stars (CVPR 2024) (0) | 2025.01.13 |
|---|---|
| Paper review: DCNv4 (CVPR 2024) (0) | 2024.09.05 |
| Paper review: InternImage (CVPR 2023) (0) | 2024.08.11 |
| Paper review: DCNv1 (ICCV 2017) (0) | 2024.07.25 |
| Paper review: SHViT (CVPR 2024) (0) | 2024.05.31 |